

Mysterious stuff
When talking to people about machine learning (ML) or artificial intelligence (AI), I often have the impression that those are perceived as either something mythical or at least very abstract for my counterpart. Such feelings can be justified because ML&AI often are not clearly defined in the given context and, more importantly in my view, they do involve at some point a fair amount of math, coding, and data wrangling, which most people are not familiar with.
On the other hand, ML&AI are here to stay. Especially, generative AI (gen-AI) in the form of large language models (LLMs), like OpenAI’s ChatGPT, Anthropic’s Claude, or Google’s Gemini (??!) are triggering a flurry of downstream applications, such as coding assistants or “productivity tools” more generally. These could lead to fundamental changes in workplaces and society more widely when projected over longer horizons.
So, it is big stuff which most people have little understanding of, and which, rightly so, makes many people worry about things which could go wrong along the way. However, I do think that ML&AI can be understood fundamentally in intuitive terms. Such an understanding does not necessarily help with designing technical algorithms in the field, but it can help people to feel at ease with these new technologies and to inform discussions about their use and regulation.
The delivery of this understanding is the goal of this post.
Definitions
Let us first set the scene. ML is a set of “data-driven models” (more on this in a moment) which make predictions based on some input data. For example, if I have a ML model to forecast economic growth in three months from now, I may feed it with a set of currently observed economic variables and then get a number. ML is therefore so powerful because it often produces more accurate predictions than many other tools we used previously, and because it can be applied to any situation where I have the right input data to model the desired target. And the abundance of data is only increasing as society digitises.
‘Modern AI’ – here and as often understood in current debates – is a subclass of ML models, namely, so-called deep artificial neural networks or systems based on deep learning. These also lie at the heart of the latest gen-AI models and their applications. For completeness, ‘traditional AI’ is a much broader field which encompasses ML. That is, the relation is the other way round, as AI then refers to any approach that aims to model or mimic intelligence.
Let us get to the actual meat of the story.
The key defining property of modern ML models, and therefore AI as well, is their universal approximation capability. This means that such a model will make perfect predictions, on average, if it has had enough data to learn from. “Perfect” here means based on a chosen measure of accuracy, which is certain to be reached given enough data. “On average” means that a single prediction can always be affected by noise and therefore be off the mark by a wide margin, as is common for any statistical model. However, if you make many predictions the chance of being far off overall will decrease. To “learn” means to set internal model parameters based on observed data according to some optimisation algorithm.
The latter bit is the mathy bit, which not everybody needs to understand to be able to discuss modern AI. So, the only bit we need to understand is what “learning from data” means such that we can describe almost any object given enough data – that is, universal approximation.
Deep dive detour
Imagine you enjoy watching fish underwater. To do so you travel to some tropical place where they (still) have nice coral reefs and board a tour on a little yellow submarine to watch marine life. It is steamy inside the vessel, and the hatches are covered with vapor. It is impossible to see anything on the outside. However, once you have meticulously cleared enough of the panel in front of you, you can see, identify, and even draw all the fish you see. You are very happy.
The problem of the steamy window which needs to be cleared up to see through is analogous to a model which needs to have seen enough data to be able to describe the object on the other side. This is depicted in Figure 1. We (or an ML model for that matter) want to classify the fish behind the panel but cannot see through it (A). We start to clear bits of it which corresponds to giving the ML model some data to learn from. This data may not be enough to make an inference about what is in front of us (B). However, once we have enough data, the view is clear, and we (the model) can see what fish there is (C). Now, a gen-AI model, the modern AI stuff, could be asked to draw its own fishes based on the observed data. Depending on the quality of learning and the query details, these may look differently compared to the ones the model learned from (D).
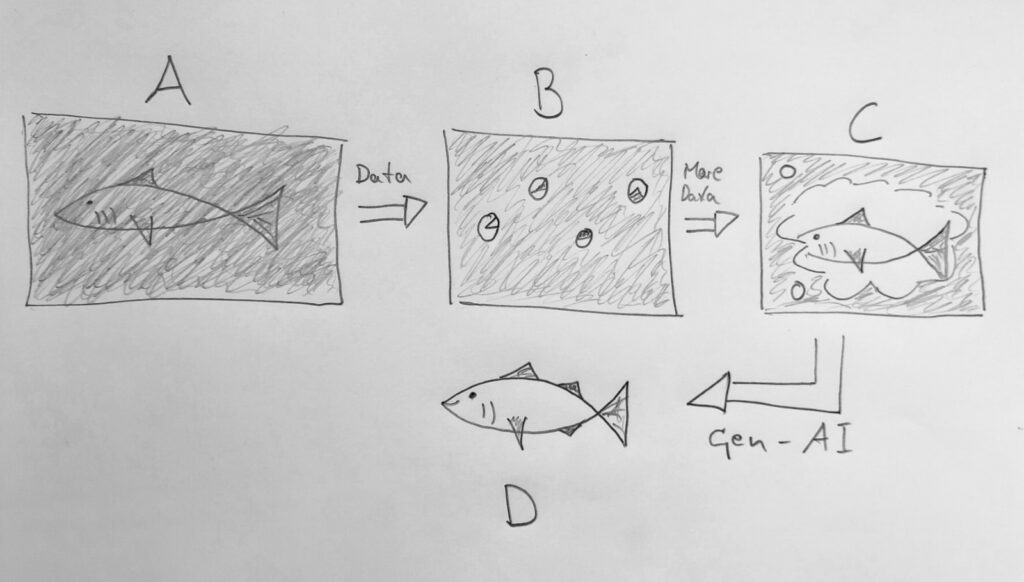
This ability to model almost arbitrary objects from data is the universal approximation capability. Many ML models have it, like neural nets, but also tree-based models like random forests, or support vector machines, to name a few. While understanding some of these and their differences in more detail requires going into more technical and mathy aspects, an understanding of what learning from data means is enough to for an intuitive understanding of those models. And this principle is the same for economic forecasting, image classification, or text generation.
Afterthoughts
The ML models discussed here learn by matching observed input data to the corresponding target observations, bit by bit. The differences between models are the technical algorithms of how this matching is done. One aspect which sets deep learning apart from other ML approaches is that these models ‘learn representations’ of real-world objects. This process corresponds to clearing the window panel in Figure 1 at different points while memorising the distinct parts of the fish, like a fin here or a tail there (B). This gives the whole thing when put together (C).
While modern AI models can be great predictors in this way, the word memorising is key. There is a debate, which will stay with us for the foreseeable future, about how intelligent modern AI models or their systems are. According to the above definition, intelligence is the “ability to learn understand, and make judgement or have opinions that are based on reason.” Many modern AI models tick most of these boxes. However, the crucial one is understanding.
Importantly, it is possible to make good predictions about something without understanding the concepts of the underlying processes. For example, most people will be able to predict that the sun will rise tomorrow without understanding Newtonian gravity. The ones who do will be able to predict the eclipses as well.
A potential avenue to address the question of understanding within modern AI models may be to investigate the representations of objects and concepts learned within such models (the existence of the latter does not seem obvious). This could be done by looking at causal or knowledge graphs formed by the learned representations and their relationships, and to investigate how similar those are to the ones humans carry in their heads. If sufficiently similar, modern gen-AI models may offer a fruitful way forward on the journey to artificial general intelligence.
If not, we may have to go back to square one since we did not understand!
Leave a Reply